Accelerate

Nicole Forsgren, Jez Humble, Gene Kim
How to measure the performance of an engineering team, and what capabilities to invest in to drive higher performance. A great entry point to audit an existing team.
This book has been recommended to me when I was focusing on improving the quality of software shipped in an already swift.
4 metrics for software delivery performance
While there are many topics covered by the book, I keep coming back regularly to a single chapter: the one about measuring software delivery performance.
Based on the result of their research, the authors present four metrics to gauge performance.
- Lead Time: time it takes to go from code committed to code successfully running in production
- Deployment Frequency: how often new code is deployed to production
- Mean Time to Restore (MTTR): How long does it take to restore a service when an incident occurs (unplanned outage, service impairment)
- Change failure rate: what percentage of changes to production results in degraded service or require remediation (lead to service impairment, require a hotfix or a rollback)
Those metrics cover both velocity (lead time & deployment frequency) and reliability (mean time to restore and change failure rate) matters.
I really like that, with only four easily measurable metrics, one can have a good overview on how an engineering team is performing.
They are also quite high-level. Behind each metric lies a lot of engineering topics (code review, QA, CI/CD, tests, …). I found it to be a great entry-point to address areas of improvement in a team.
Lead Time
👉 Time it takes to go from code committed to code successfully running in production
| High Performers | Medium Performers | Low Performers | |
|---|---|---|---|
| Lead Time | Less than one hour | Between one week and one month | Between one month and six months |
While this definition is just a subpart of the global lead time (from idea to production), it has the virtue of focusing on a development stage the engineering team is fully responsible for and can autonomously make changes.
Some subjects to tackle to reduce lead time:
- Pull Request & Code Review best practices
- CI/CD pipelines
- QA processes
Deployment frequency
👉 How often new code is deployed to production
| High Performers | Medium Performers | Low Performers | |
|---|---|---|---|
| Deployment frequency | On demand (multiple deploys per day) | Between once per week and once per month | Between once per month and once every six months |
Instead of deployment frequency, an ideal measure here would be batch size.
Small batch size reduces cycle times and variability in flow, accelerates feedback, reduces risk and overhead, improves efficiency, increases motivation and urgency, and reduces costs and schedule growth.
However, batch size is hard to measure. Therefore, deployment frequency is a good proxy for batch size as there is usually a strong correlation between the two: high frequency deployment implies small batch size, and vice versa.
Some subjects to tackle to increase deployment frequency:
- CI/CD pipelines
- Feature flags
- Software architecture
Mean Time to Restore (MTTR)
👉 How long does it take to restore a service when an incident occurs (unplanned outage, service impairment)
| High Performers | Medium Performers | Low Performers | |
|---|---|---|---|
| MTTR | Less than one hour | Less than one day | Between one day and one week |
Failure is inevitable, so the key question is: How quickly can service be restored ?
Some subjects to tackle to reduce MTTR:
- Monitoring (how incident are detected)
- Alerting
- Tech bandwidth for support
- Prioritization
Change failure rate
👉 What percentage of changes to production results in degraded service or require remediation (lead to service impairment, require a hotfix or a rollback)
| High Performers | Medium Performers | Low Performers | |
|---|---|---|---|
| Change failure rate | 0-15% | 16-30% | >30% |
This is a key quality metric highlighting how good a delivery process is.
Some subjects to tackle to reduce change failure rate:
- Code Review process
- Test automation
- QA processes
The book gives then pointers on measuring and changing culture depending on the organizational structure you are currently in: pathological (Power-oriented), bureaucratic (Rule-oriented) or generative (Performance-oriented).
It also addresses topics such as Continuous Integration, loosely coupled architecture, InfoSec, lean management, lean product development, …
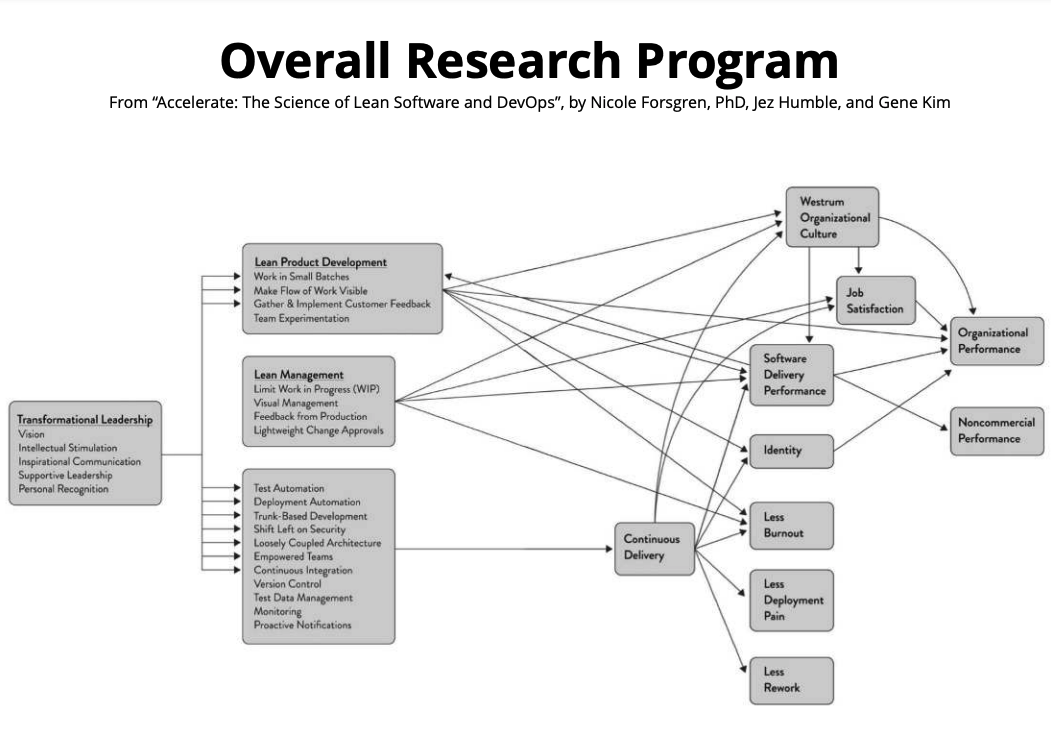
Lastly, there is a whole section dedicated to the research process (based on surveys) and the statistical analysis made to come up with the insight presented in the book. It goes into great details and gives strong legibility to the insights discovered. It is not too often we see it in opinionated software engineering books.
Long story short: Accelerate is a great resource for anyone interested in measuring and improving the performance of an engineering team. A must-read !